list如何去重
简单数字可以使用hashset去重
public class Test {
public static void main(String[] args) {
List list = new ArrayList();
list.add(11);
list.add(12);
list.add(13);
list.add(14);
list.add(15);
list.add(11);
System.out.println(list);
Set set = new HashSet();
List newList = new ArrayList();
set.addAll(list);
newList.addAll(set);
System.out.println(newList);
}
}
但是这个用法如果只复杂对象,必须重写equal()和hashcode()方法。
根据实际情况来重写这两个方法。
集合比较
两个集合equal()比较,比较的是引用的类型。集合内引用类型如果是基本数据类型short、byte、char、int、double、float、long、boolean是不会比较引用地址的。
反之,复杂类型是会比较地址的。
User user = new User(1, "lin");
ArrayList<User> one = new ArrayList<>();
one.add(new User(1, "lin"));
Vector<User> two = new Vector<>();
two.add(new User(1, "lin"));
System.out.println(one.equals(two)); //false
包装类不会
ArrayList<Integer> one = new ArrayList<>();
one.add(new Integer(1));
Vector<Integer> two = new Vector<>();
two.add(new Integer(1));
System.out.println(one.equals(two)); //true
Arrays.asList转换的坑
基本数据类型的数组转换为集合,整个对被当作一个对象处理。
包装类或者复杂类型的不会。因为基本数据类型无法充当泛型T。
// 基本数据类型整个作为一个对象转换为集合。包装类不同。
int[] test = new int[]{1, 2, 3, 4};
long[] longs = new long[]{1L, 2L, 3L, 4L};
String[] strings = new String[]{"1", "2", "3"};
List ints = Arrays.asList(longs);
System.out.println(ints.size());
源码解析:

此外:这个add操作会报错java.lang.UnsupportedOperationException,转化的数组只能查看,不能编辑。
Integer[] test1 = new Integer[]{1, 2, 3, 4};
List<Integer> list = Arrays.asList(test1);
//list.add(5); 错误的修改方法
ArrayList<Integer> list1 = new ArrayList<>(Arrays.asList(test1));
list1.add(5);
++i 和 i++
简单的理解就是i++是先访问i然后再自增,而i++则是先自增然后再访问i的值。
// j++其实还没有数字变化。但是++j就有变化了。++j 100
int j = 0;
for (int i = 0; i < 100; i++) {
j = j++;
}
System.out.println(j); // 0
for循环里面的值操作会一个个执行,有先后,所以为2
public static void main(String[] args) {
int i = 0;
if (i++ >= 0 && i++ > 1 && (++i) < 3) {
System.out.println("条件成立");
}
System.out.println(i); // 2
}
异常return顺序
- 在trycatch中使用return
- return的基本数据类型是类似
栈,先返回后面入栈return的值。注意其中的变量值是会更新的。继续操作该变量。复杂对象引用修改也会更新对象值。 - 如果是返回List这些堆里面的数据,则没有任何影响。
- 尽量不要在finally中返回值,一般都是关闭流的操作。
@SuppressWarnings("finally")
public static int testBasic(){
int i = 1;
try{
i++;
int m = i / 0 ;
System.out.println("try block, i = "+i);
return i;
}catch(Exception e){
i ++;
System.out.println("catch block i = "+i);
return i;
}finally{
// i = 10;
i++;
System.out.println("finally block i = "+i);
return i;
}
返回结果:4
如果finally释放i = 10;注释i++返回:10
静态代码块执行顺序
静态代码块只会构造一次,并且优先,其他的就父类优先。
静态代码块>代码块>构造函数
class staticCode {
static {
System.out.println("父静态代码块");
}
{
System.out.println("父非静态代码块");
}
public staticCode() {
System.out.println("父构造函数");
}
}
public class staticCode_1 extends staticCode {
static {
System.out.println("子静态代码块");
}
{
System.out.println("子非静态代码块");
}
public staticCode_1() {
System.out.println("子构造函数");
}
public static void main(String[] args) {
new staticCode_1();
System.out.println("------------------------");
new staticCode_1();
}
}
父静态代码块 子静态代码块 父非静态代码块 父构造函数 子非静态代码块 子构造函数 ------------------------ 父非静态代码块 父构造函数 子非静态代码块 子构造函数
新建一个1M的数组
因为int是java的基本数据类型,它的默认值是0;Integer默认是null
一个boolean,byte类型占用1个字节。short,char 2字节,int,float 类型占用4个字节,1024字节为1KB
int[] arr = new int[1024 * 1024 / 4];
包装类型的比较
包装类可以直接equal
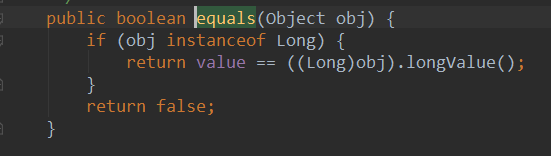
User user1 = new User(2L);
user1.setAge(12D);
User user2 = new User(2L);
user2.setAge(12D);
// 包装类可以直接equal
if (user1.getId().longValue() == user2.getId().longValue()) { //true
if (user1.getId().equals(user2.getId())) { //true
System.out.println("=====");
}
}
if (user2.getAge().equals(user2.getAge())){ // true
System.out.println("==double==");
}
内存泄漏
list有对object的强引用。gc无法回收。
public static void main(String[] args) {
//置空,gc下个回合会回收对象,容器占用资源,List仍然有对象的引用,无法回收。
List list = new ArrayList<>(10);
for (int i = 0; i < 100; i++) {
Object object = new Object();
list.add(object);
object = null;
}
}
一次排序选第二大的数
public static void main(String[] args) {
int[] a = new int[]{222,223, 22, 77, 33, 11, 55, 8, 9, 5};
int Max = a[0];
int SecondMax = a[1];
for (int i = 2; i < a.length; i++) {
// 从第三个开始循环,如果元素大于最大值,则最大值更新,原最大值赋给第二大值
if (a[i] > Max) {
SecondMax = Max;
Max = a[i];
}
// 如果该元素不大于最大值,且大约第二大的值,则第二大的值更新
if (a[i] > SecondMax && a[i] < Max)
SecondMax = a[i];
}
System.out.println(Max);
System.out.println(SecondMax);
}
clone深_浅拷贝
- 浅拷贝:
实现Cloneable接口,重写clone()方法。
public class Student implements Cloneable{
private String name;
public String getName() {
return name;
}
public void setName(String string) {
this.name = string;
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
测试:
public static void main(String[] args) throws CloneNotSupportedException {
Student student = new Student(); //对象中没有复杂类型时
student.setName("张三");
System.out.println(student.toString() + student.getName());
Student clone = (Student)student.clone();
System.out.println(clone.toString() + clone.getName());
}
clone深_浅拷贝.Student@1540e19d张三 clone深_浅拷贝.Student@677327b6张三
可以看到地址是不同的对象。里面的名称是一样的。
- 深拷贝
复杂对象时,需要自己先重写克隆方法。
其中克隆方法也实现对老师类的克隆。student.teacher = (Teacher) teacher.clone();这样就不会时对老师的引用了。
public class Student implements Cloneable{
private String name;
private Teacher teacher;
public String getName() {
return name;
}
public void setName(String string) {
this.name = string;
}
public Teacher getTeacher() {
return teacher;
}
public void setTeacher(Teacher teacher) {
this.teacher = teacher;
}
@Override
protected Object clone() throws CloneNotSupportedException {
Student student = (Student) super.clone();
student.teacher = (Teacher) teacher.clone();
return student;
}
@Override
public String toString() {
return "Student [name=" + name + ", teacher=" + teacher + "]";
}
}
老师类:
老师类也实现克隆方法,
public class Teacher implements Cloneable {
private String name;
public Teacher(String name) {
this.name = name;
}
public Teacher() {
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
@Override
public String toString() {
return "Teacher [name=" + name + "]";
}
}
测试类:
public static void main(String[] args) throws CloneNotSupportedException {
Student student = new Student(); //对象中没有复杂类型时
student.setName("张三");
Teacher teacher = new Teacher();
teacher.setName("张三老师");
student.setTeacher(teacher);
Student clone = (Student) student.clone();
teacher.setName("李四老师");
System.out.println(student.toString());
System.out.println(clone.toString());
}
另外:集合类是没有Cloneable和Serializable接口 因为:单单克隆一个集合是没有意义的,重点是里面装的内容。所以要手动实现
更新:
深拷贝有很多类型,有集合内嵌复杂对象,有Map复杂对象,对象层级比较多的时候,clone方法要写很长,可以使用序列化的方式。
/**
* 使用对象的序列化进而实现深拷贝
* @param <T>
* @param obj
* @return
*/
private <T extends Serializable> T byteClone(T obj) {
T cloneObj = null;
try {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(obj);
oos.close();
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bis);
cloneObj = (T) ois.readObject();
ois.close();
} catch (Exception e) {
e.printStackTrace();
}
return cloneObj;
}
再次更新:
使用 jdk 序列化性能在高并发的情况下有所损耗,可以替换 Kryo 序列化方式,使用方法也比较简单,引入依赖,
Kryo kryo = new Kryo();
kryo.setRegistrationRequired(false);
kryo.copy(user)
字符串问题
Java中的常量池实际上分为两种形态:静态常量池和运行时常量池。
静态常量池即是*.class文件中的常量池,用来存放方法名称、字段名称等。
运行时常量池则是我们常说的常量池,用来存放常量(final关键字修饰的变量)和字符串等,避免频繁的创建和销毁对象而影响系统性能,实现了对象的共享(即大家用的都是同一个东西)。
String s1 = "Hello";
String s2 = new String("Hello");
String s3 = s2.intern();
String s4 = "Hel" + "lo";
String sa = "Hel";
String sb = "lo";
String s5 = sa + sb;
System.out.println(s1 == s2);// false
System.out.println(s1 == s3);// true
System.out.println(s1 == s4);// true
System.out.println(s1 == s5);// false
- ①String的
intern()方法会查找在常量池中是否存在一份equal相等的字符串,如果有则返回该字符串的引用,如果没有则添加自己的字符串进入常量池。 - ②虽然s4是动态拼接出来的,但所有参与拼接的部分都是已知的字面量,在编译期间,这种拼接会被优化,编译器直接帮你拼好,因此相等。 (只有使用这种全部带引号、使用“+”连接产生的新字符串对象才会被加入字符串池中)
- ③虽然s5也是拼接,但sa和sb作为两个
变量,都是不可预料的,并不会被优化,会存放到堆中。
字符串直接相加操作,直接操作字符串常量池。相等。
字符串
对象变量相加操作,对象不会放到堆中。不等。
intern():查找在常量池中是否存在一份equal相等的字符串,如果有则返回该字符串的引用,如果没有则添加自己的字符串进入常量池
循环创建对象
两种写法,那个更优!
Object obj = null;
for (int i = 0; i < 10000; ++i) {
obj = new Object();
}
for (int i = 0; i < 10000; i++) {
Object object = new Object();
}
正解: 两种方法都在堆积创建了10000个对象,声明在外面就省了栈里的一点内存,但是导致obj变量生命周期变长,影响GC,另外第一种不注意还会引入bug,建议第二种。
线程池大小评估
100~10000的短任务(3秒),半个小时完成,线程池起多少个线程合适,用哪个线程池实例对象。
10000x3 / 30x60 约等于 17,所以最大 20 个线程足以。
最好用 ThreadPoolExecutor 创建吧,17个线程可以在30分钟完成任务,最大线程可以开到20,但是考虑到最少可能只有100个任务,一个线程30*60/3=600个任务,考虑权衡处理时间和任务数,corePoolSize 可以3个,maximumPoolSize 可以20个,keepalivetime 5秒
利特尔法则(Little’s law)
线程池大小 = ((线程 IO time + 线程 CPU time )/线程 CPU time ) CPU数目*
具体实践
通过公式,我们了解到需要 3 个具体数值
- 一个请求所消耗的时间 (线程 IO time + 线程 CPU time)
- 该请求计算时间 (线程 CPU time)
- CPU 数目
cat /proc/cpuinfo| grep "processor"| wc -l